1. ¿Qué es la gestión y monitorización de la red?
2. Necesidades de gestión y monitorización de la red
3. La gestión de la red
4. SNMP
5. Funcionamiento de SNMP
6. Las MIBs
7. Las MIBs privadas
8. Sistemas de gestión/monitorización de red más importantes
1. ¿Qué es la gestión y monitorización de la red?
Lo primero que debemos hacer es contextualizar qué es la gestión de red. Debemos entender el concepto de gestión de la red como la capacidad de monitorizar y controlar los recursos existentes en una red informática.
Podríamos decir que la gestión conlleva la capacidad de poder configurar cosas en la red, es decir, poder cambiar parámetros, desactivar interfaces, etc. mientras que la monitorización se refiere exclusivamente a la posibilidad de visualizar determinada información, como flujos de datos en los interfaces, uso de CPU y memoria, etc.
Es decir, podemos entender por monitorización de red el uso de equipos o sistemas que constantemente monitorizan otros equipos o dispositivos de red de diversas maneras o usando determinados protocolos como SNMP con el objeto de recabar información de su estado e informar al administrador de la red en cado de caídas o alcances de umbrales preestablecidos.
Se puede considerar que la monitorización de red es un subconjunto del concepto de Gestión de Red.
Por todo ello, cuando hablamos de gestión de la red, solemos referirnos a ambas prestaciones unidas: gestión y monitorización de la red. Normalmente los sistemas de gestión, tanto GNU como comerciales, permitirán cubrir ampliamente ambos aspectos.
Por eso, a partir de ahora siempre que hablemos de gestión de la red, nos estamos refiriendo simultáneamente a la gestión y a la monitorización de la misma, que aunque son cosas distintas casi siempre irán de la mano en los sistemas habituales.
2. Necesidades de gestión y monitorización de la red
Las necesidades de gestión de redes han ido aumentando cada vez más a medida que se ampliaba la complejidad de las redes locales y han proliferado las interconexiones entre redes.
El poder conocer el estado de interfaces, niveles de tráfico, índice de errores, etc. se ha hecho cada vez más necesario e interesante a medida a aumentaba las necesidades de comunicación.
Todo ello con una interfaz agradable y cómoda para el usuario.
Podemos decir que las necesidades de gestionar una red viene dadas por:
- Aumento en la complejidad de las interconexiones locales.
- Aumento de las necesidades de interconexión entre redes locales diferentes.
- Uso de varios protocolos relacionados en las aplicaciones.
- Justificación de inversiones en tecnologías de comunicaciones.
- Control de la red.
- La gestión de la red
3. La gestión de Red
La gestión de red es uno de los puntos más controvertidos en el mundo de las Telecomunicaciones. Existen varias alternativas pero no una única aceptada por todos. Las soluciones operativas son por lo general de tipo propietaria, como HP Open View, IBM Netview, etc. Ello supone que en una red con elementos de varios fabricantes no existe una plataforma única que integre todos los elementos de la red. El hecho de tener varias plataformas de gestión complica bastante las tareas de gestión.
No obstante en la actualidad existen dos tendencias claras: SNMP y CMIS/CMIP. La primera predomina en redes privadas y la segunda en redes públicas.
4. SNMP
El protocolo SNMP se creó a mediados de los años 80 como una solución temporal para la gestión de dispositivos antes de que fueran desarrollados y estandarizados métodos y protocolos bien definitivos de gestión de red. Esos protocolos de gestión no se llegaron a realizar y la primera versión de SNMP que la podemos llamar SNMPv1, se convirtió en la mejor opción de gestión medianamente aceptada por los fabricantes.
SNMP fue desarrollado por Case, McCloghrie, Rose, y Waldbusser. Las siglas significan Simple Network Management Protocol: protocolo de gestión de red simplificado. No pretendía, pues, ser una solución definitiva. Por ese motivo, y una vez que se vió como la única alternativa, se desarrolló la versión 2 del protocolo; al se suele denominar SNMPv2.
Diferencias entre la versión 1 y la 2.
- Un desarrollo más complejo de las variables permite obtener información más depurada.
- En la versión 1 no existían mecanismos de seguridad, que se incluyeron en la versión 2.
- Se añadió la posibilidad de estructuraa la información en modo de tablas de datos, lo cual amplía el número de objetos gestionables.
En la actualidad se dispone ya de la versión 3, la cual implementa métodos fiables de autenticación, privacidad y autorización. Así como permite el uso de lenguajes orientados a objetos (como JAVA, C++, etc) para la construcción de los elementos de protocolo.
No obstante la SNMPv3 no ha sido aún bien aceptado por la industria y es minoritariamente utilizado.
Los RFCs más importantes relacionados con SNMP son:
| RFC 1155 | SMI (Estructura de la Información de Gestión) |
| RFC 1157 | SNMP (Protocolo Simple de Gestión de red) |
| RFC 1213 | MIB-II (Base de Información de Gestión para la gestión de red) |
| RFC 1215 | Convención para definir Traps para el uso con SNMP |
| RFC 1441 | Introducción a SNMPv2 |
| RFC 1757 | MIB de Monitorización Remota de Red |
En la siguiente figura se representa el esquema básico de un proceso de gestión basado en SNMP:
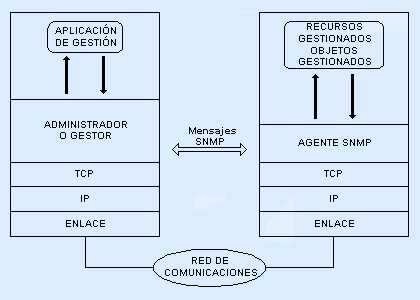
Como vemos, SNMP define el mecanismo de mensajes que permite al sistema de gestión de red, normalmente un programa o paquete de software de gestión, comunicarte con un elemento de la red, llamado agente SNMP.
5. Funcionamiento de SNMP
SNMP define un mecanismo de comunicación entre el sistema de gestión de red y lo que hemos llamado el agente a gestionar. En realidad, debemos entender por agente a otro software que reside en el equipo gestionado y es el que se encarga de recopilar la información específica y ponerla a disposición des sistema de gestión.
SNMP comporta una serie de mensajes entre el sistema de gestión y el agente. Estos mensajes se pueden clasificar en:
Operaciones de lectura. Utilizado por el sistema de gestión para supervisar elementos de red. Lo que hace el sistema de gestión es pedir el valor de difernter variables que son mantenidas por los dispositivos administrados.
Operaciones de escritura. En este cado el sistema de gestión tiene la potestad de cambiar los valores de las variables almacenadas dentro de los dispositivos administrados.
Operaciones de notificación. Es este caso son los dispositivos administrados los que reportan eventos hacia el sistema de gestión. Cuando cierto tipo de evento ocurre, por ejemplo una caída de interfaz o enlace, un dispositivo administrado envía una notificación al sistema de gestión de red.
Por otra parte existen también una serie de operaciones transversales que son usadas por los sistemas de gestión para determinar qué variables soporta un dispositivo administrado y para recoger secuencialmente información en tablas de variables, como por ejemplo, una tabla de rutas.
6. Las MIBs
Ahora cabría preguntarnos ¿qué tipo de información o qué variables puede pedir un sistema de gestión de red al dispositivo gestionado? Dicho de otro modo ¿qué colección de variables existen?
El conjunto de variables posibles están estandarizadas en lo que se ha dado en llamar las MIBs (Management Information Base). Una MIB es una base de datos de variables disponibles en los equipos y que pueden ser accedidas mediante algún protocolo de mensajes como SNMP.
Una MIB es, pues, básicamente una base de datos de variables. Pero las MIBs además están jerarquizadas, cada variable se encuentra encuadrada en una posición dentro de la jerarquía. Esta jerarquía sigue una topología de árbol y las variables se sitúan en una rama o posición dentro del árbol MIB.
A las variables MIBs se las llama objetos. Cada objeto está identificado con un identificador, el OID (Objet ID). Cada OID ocupa una posición en la jerarquía MIB, en la que existe una raíz que llamamos anónima y unos niveles que son asignados por diferentes organizaciones.
Una representación de árbol MIB podría ser es siguiente:
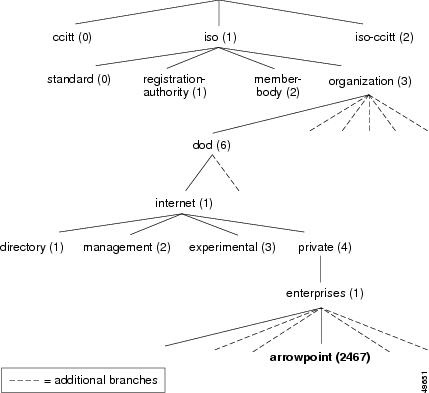
Cada posición en el árbol MIB tiene asociado un número y un nombre. La manera de identificar a una variable MIB es por su posición en la jerarquía de números separados por un punto o por los nombres asociados. Los nombres de las distintas posiciones en la jerarquía están asociados a estándares y organizaciones.
Las variables estándares que se pueden consultar mediante SNMP se encuadran bajo la llamada MIB-II y todas las variables pertenecientes a dicho grupo están bajo la rama identificada como:
1.3.6.1.2.1.....
o lo que es lo mismo:
iso.org.dod.internet.mgmt.mib-2.....
Dentro de estas MIB-II las variables están a su vez agrupadas bajo diversas rfcs temáticas, así la rfc1213 hace referencia a variables del sistema y se identifica con la posición 1 y nombre System, es decir este grupo de variables tiene el identificador:
1.3.6.1.2.1.1
o lo que es lo mismo:
iso.org.dod.internet.mgmt.mib-2.system
Bien, dentro del grupo de variables System de la MIB-II existe por ejemplo una variable con identificador 1 y nombre sysDescr que pretende ser una descripción del sistema. El path, identificador o nombre de dicha variable es:
1.3.6.1.2.1.1.2
o lo que es lo mismo:
iso.org.dod.internet.mgmt.mib-2.system.sysDescr
La documentación estandard suele describir una variable así de la siguiente manera:
OID value: 1.3.6.1.2.1.1.1
OID description:
sysDescr OBJECT-TYPE
SYNTAX DisplayString (SIZE (0..255))
ACCESS read-only
STATUS mandatory
DESCRIPTION
"A textual description of the entity. This value
should include the full name and version
identification of the system's hardware type,
software operating-system, and networking
software. It is mandatory that this only contain
printable ASCII characters."
::= { system 1 }
Así por ejemplo, en el caso del fabricante Extreme Network, al leer dicha variable por software se nos devuelve la cadena:
STRING: "ExtremeXOS version 12.0.2.25 v1202b25 by release-manager on Tue Nov 6 23:27:20 PST 2007"
Vemos que no necesitamos que nos den el path completo de una variable sino sólo su nombre y a qué rama de la MIB-II está asociada, osea, a qué RFC pertenece.
7. Las MIBs privadas
Los fabricantes habitualmente implementan variables específicas para sus equipos, recogiendo información adicional o que no se incluye en la MIB-II estándar. A estas ramas de la MIB específicas de cada fabricante se las denominan MIBs privadas.
Las MIBs privadas se encuadran siempre bajo la rama:
1.3.6.1.4.1
o lo que es lo mismo:
iso.org.dod.internet.private.enterprise
Las MIBs privadas las documenta el fabricante del hardware y software al que se destina dicha MIB y del mismo modo que la MIB-II se organizan en grupos o tablas de variables.
Muchas veces se incluyen un montón de variables no implementadas o soportadas aún por el software pero que están definidas para un uso futuro sin tener que ampliar la MIB.
Para que un visualizador o browser del arbol MIB pueda reconocer las MIBs privadas, debe disponer de sus definiciones, las cuales usualmente las proporciona el fabricante del hardware en un archivo de texto con extensión *.MIB (o *.txt). Sin ese archivo nuestro MIB browser no es capaz de visualizar ni nombrar la variables bajo el OID 1.3.6.1.4.1.
Por ejemplo, analizando el archivo 11.6.3.5_MIB.txt correspondiente a la MIB privada de un switch Extreme Network, vemos que lo primero que se identifica es al fabricante mediante un número y nombre que colgará de la rama iso.org.dod.internet.private.enterprise. En el caso del fabricante Extreme Network el identificador numérico es 1916, nombrado como «extremenetwork»,
-- Organization & Product branches
extremenetworks MODULE-IDENTITY
LAST-UPDATED "0211230000Z"
ORGANIZATION "Extreme Networks, Inc."
CONTACT-INFO "www.extremenetworks.com"
DESCRIPTION "Extreme Wireless Access Tables"
::= { enterprises 1916 }
por lo que las variable privadas estarán bajo el path:
1.3.6.1.4.1.1916
o lo que es lo mismo:
iso.org.dod.internet.private.enterprise.extremenetwork
Dentro de dicha estructura Extreme define un sinfín de variables agruparas lógicamente. El archivo descriptor de la MIB posee más de 30.000 líneas y maneja más de 17.000 identificadores distintos.
Indicar también que mucha MIBs privadas incluyen un subconjunto de la MIB-II e incluso complementan la misma MIB-II añadiendo identificadores dentro de su estructura.
8. Sistemas de gestión/monitorización de red más importantes
Una buena tabla comparativa de aplicaciones de monitorización de red se puede encontrar en:
http://en.wikipedia.org/wiki/Comparison_of_network_monitoring_systems
Realizar un estudio pormenorizado y comparativo de cada una de ellas puede llevar bastante tiempo. Como comentario podemos decir que Nagios es GNU y desarrollado para Linux. Podemos considerarlo un referente dentro del mundo GNU por ser uno de los más extendidos. Otras de las opciones bastante utilizadas es Pandora FMS. Pandora se ejecuta en un servidor PHP y la monitorización en la consola cliente se realiza desde un navegador web. Usa una base de datos MySQL para el almacenamiento. Permite la presentación gráfica en mapas. Opsview es un sistema que integra las herramientas Nagios Core, Nagvis, Net-SNMP y RRDtool. Spiceworks Es un software diseñado para Windows con licencia Free pero no GPL. Los clientes son de tipo web. TclMon está escrito en Tcl y se instala teóricamente en cualquier S.O. con Tcl aunque en su web recomiendan Sun Solaris. El cliente de monitorización es una aplicación Windows llamada Netstate. Su página web es: http://tclmon.sourceforge.net/. Por último Zabbix es un software para clientes web con PHP. Página web: http://www.zabbix.com/es/